
Die Integration von künstlicher Intelligenz (KI) in Unternehmen ist heutzutage kein Luxus mehr, sondern eine Notwendigkeit. Bei AMCON arbeiten wir daran, effiziente und sichere KI-Systeme zu entwickeln, um unsere internen Prozesse zu optimieren. Ein besonderer Fokus liegt dabei auf der Entwicklung eines lokalen Large Language Models (LLM). Dieses arbeitet mit Retrieval-Augmented Generation (RAG) und ReACT-Agenten. Der Datenschutz steht dabei im Vordergrund: Alle Daten verbleiben auf lokalen Servern und werden nicht ins Internet übertragen.
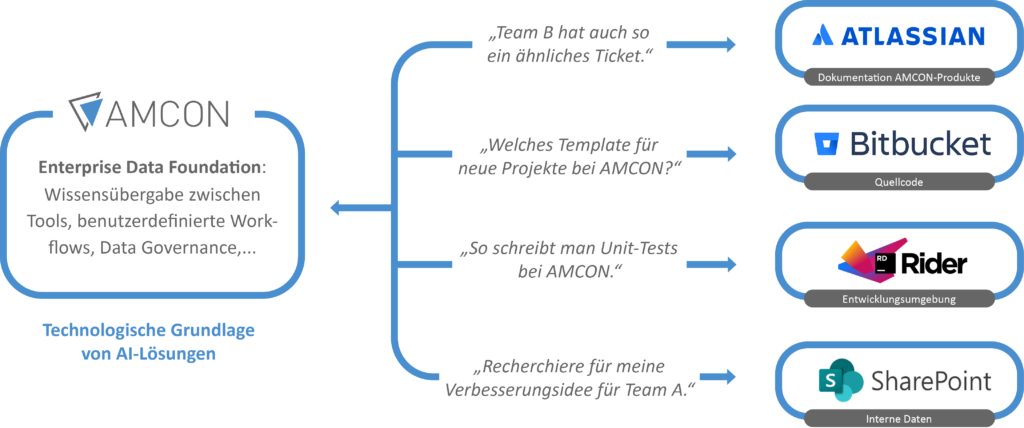
Terminologien und Grundlagen der KI
Was sind LLMs?
Large Language Models (LLMs) wie GPT-4, Llama 3.2 oder Gemini 2.0 sind KI-Systeme, die darauf trainiert sind, natürliche Sprache zu verarbeiten und zu generieren. Sie können Texte analysieren, Zusammenfassungen erstellen oder Code generieren. Diese Modelle basieren auf Transformer-Architekturen und verwenden Mechanismen wie „Attention“, um kontextbezogene Vorhersagen zu treffen.
Embedding & RAG
Embedding-Modelle wandeln Text in Zahlenvektoren um, die es KI-Systemen ermöglichen, Beziehungen zwischen Wörtern, Sätzen oder Dokumenten zu erkennen. RAG (Retrieval-Augmented Generation) verbessert LLMs durch die Integration externer Wissensquellen. Das bedeutet, dass das Modell nicht nur auf bereits gelernten Daten basiert, sondern auch relevante Informationen aus internen Datenbanken oder Dokumenten abrufen kann. Dies geschieht in zwei Phasen: der Retrieval-Phase, in der relevante Dokumente identifiziert werden, und der Generations-Phase, in der die KI eine fundierte Antwort formuliert.
ReACT-Agenten
ReACT (Reasoning + Acting) ist eine Technik, bei der KI-Agenten nicht nur auf Anfragen reagieren. Sie führen auch komplexe Entscheidungsprozesse durch. Sie kombinieren Schlussfolgerungen mit gezielten Aktionen. So können sie beispielsweise Jira- oder Confluence-Daten intelligent auswerten. Durch den Einsatz von Reinforcement Learning und regelbasierter Entscheidungsfindung können diese Agenten selbstständig Anfragen priorisieren und Aufgaben delegieren. Dabei stehen den Agenten verschiedene Werkzeuge zur Verfügung, die sie je nach Bedarf einsetzen können – z.B. das Abfragen von APIs, das Durchsuchen interner Datenquellen oder das Abrufen externer Informationen.
Anwendungsfall: Lokales LLM für AMCON
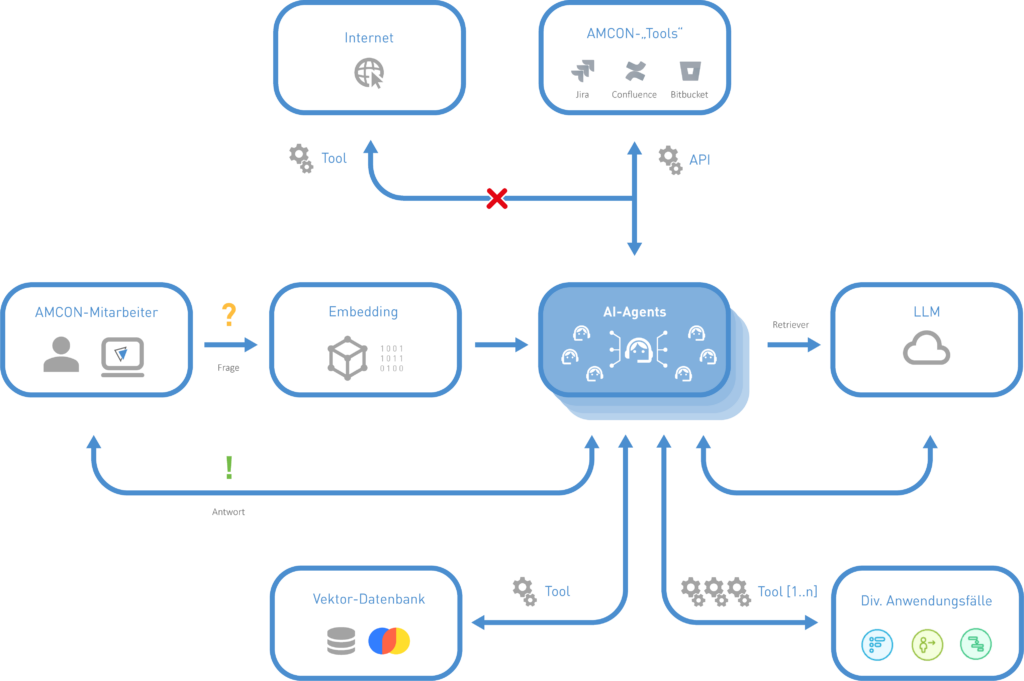
Technologische Umsetzung
Das System basiert auf mehreren zentralen Komponenten:
- Daten & Retrieval: Dokumente und Inhalte aus Jira und Confluence werden strukturiert verarbeitet und für das LLM aufbereitet. Dies geschieht durch eine Kombination aus regulären Ausdrücken zur Textextraktion und Transformer-basierten Modellen zur semantischen Analyse.
- Embedding & RAG: Die Dokumente werden in Vektoren transformiert, damit das Modell gezielt auf relevante Informationen zugreifen kann. Dazu wird das Embedding-Modell multilingual-e5-large verwendet.
- Backend & Model Access: Eine interne API verbindet verschiedene Anwendungen mit dem KI-System. Dabei werden Technologien wie FastAPI für die API-Schnittstelle und ONNX für die performante Modellinferenz eingesetzt. Der ReACT-Agent kann mit den APIs von Confluence und Jira kommunizieren, um bei Bedarf relevante Informationen abzurufen. Dies geschieht über die Atlassian Python API, die dem Agenten zur Verfügung gestellt wird und für Jira und Confluence optimiert wurde.
- Frontend: Eine benutzerfreundliche Webschnittstelle zur einfachen Interaktion mit dem KI-Modell wird noch implementiert.
- Verwendete Technologien: Für die Speicherung und Verarbeitung von Vektordaten nutzen wir ChromaDB, als Sprachmodelle setzen wir auf Llama 3.2 und Gemma.
- Langchain & LangGraph: Die gesamte Architektur wurde mit LangChain und LangGraph aufgebaut, um komplexe Interaktionen zwischen Agenten, Datenquellen und Retrieval-Mechanismen effizient zu orchestrieren.
Herausforderungen bei der Entwicklung
Datenschutz und Sicherheit
Da alle Daten lokal gespeichert werden, mussten wir sicherstellen, dass unser System nicht auf externe Server zugreift. Außerdem ist eine robuste Zugriffskontrolle erforderlich, damit nur autorisierte Benutzer auf sensible Informationen zugreifen können. Dazu setzen wir auf OAuth 2.0 und rollenbasierte Zugriffskontrollen.
Modelloptimierung
Ein LLM lokal zu betreiben, bedeutet, dass es performante Hardware-Ressourcen benötigt. Daher mussten wir das Modell optimieren, um einen guten Kompromiss zwischen Leistung und Effizienz zu finden. Hier setzen wir Techniken wie Quantisierung (z.B. mit HuggingFace’s bitsandbytes) und Knowledge Distillation ein, um Speicher- und Rechenanforderungen zu reduzieren.
Integration in bestehende Systeme
Die nahtlose Integration in Jira und Confluence war eine Herausforderung, da unterschiedliche Datenformate verarbeitet und harmonisiert werden mussten. Die Entwicklung spezieller Retriever spielte dabei eine zentrale Rolle. Eine Kombination aus schlagwortbasierten und semantischen Suchmethoden ermöglicht eine sehr effiziente und präzise Informationsbereitstellung.
Zukunftsaussichten
In den kommenden Jahren werden wir uns darauf konzentrieren, das System weiter zu verbessern:
- Optimierung des Inferenzprozesses: Schnellere und präzisere Antworten durch spezialisierte Modellarchitekturen und effizientere Implementierung der Verarbeitungspipelines.
- Erweiterung der Agentenfunktionalität: Entwicklung und Implementierung neuer KI-Agenten für spezifische Geschäftsaufgaben, u.a:
- Code Improvement Agent: Analysiert bestehenden Code, identifiziert Optimierungspotenziale und schlägt effizientere Lösungen vor.
- Onboarding Agent: Unterstützt neue Mitarbeiter bei der Einarbeitung durch Bereitstellung relevanter Dokumentationen und Unternehmensrichtlinien.
- Projektmanagement-Assistent: Hilft bei der Koordination von Aufgaben, der Zuweisung von Ressourcen und der Verfolgung des Projektfortschritts.
- Templating Agent: Automatisiert die Erstellung von Vorlagen und Standarddokumenten zur Effizienzsteigerung.
- Neue bzw. bessere LLMs: Integration neuer, leistungsfähigerer LLMs wie zukünftige Versionen von Llama, DeepSeek sowie domänenspezifische Einbettungsmodelle.
- Adaptive Werkzeugnutzung durch Agenten: Die Agenten erhalten eine flexible Toolchain, die es ihnen erlaubt, je nach Bedarf unterschiedliche Werkzeuge wie API-Abfragen, semantische Suche oder externe Datenquellen zu nutzen.
- Erweiterte Retrievalmethoden: Verbesserung des Information Retrieval durch hybride Suchtechniken, die semantische und klassische Indexierung kombinieren.
- Skalierbarkeit und Infrastruktur: Evaluierung und Implementierung neuer Hard- und Softwarelösungen zur Skalierung der KI-Architektur, z.B. durch dezentrale Verarbeitung und spezialisierte KI-Beschleuniger.
- Bessere Integration in bestehende Geschäftsprozesse: Gewährleistung einer nahtlosen Integration der KI-Lösung in bestehende Arbeitsabläufe und Anwendungen, um die betriebliche Effizienz weiter zu steigern.
Fazit
Mit der Entwicklung eines lokalen LLM-Systems hat AMCON einen wichtigen Schritt in Richtung KI-gestützter Prozessoptimierung gemacht. Durch den Einsatz von RAG- und ReACT-Agenten kann Unternehmenswissen effizienter genutzt werden, ohne Kompromisse beim Datenschutz einzugehen. Die Zukunft der KI bei AMCON liegt in der kontinuierlichen Weiterentwicklung dieser Technologien, um einen maximalen Mehrwert für die Mitarbeiter zu schaffen. Gleichzeitig setzen wir auf eine enge Verzahnung mit bewährten DevOps- und MLOps-Strategien, um den Entwicklungszyklus effizient zu gestalten und eine kontinuierliche Verbesserung zu gewährleisten.