
Integrating artificial intelligence (AI) into business processes is no longer a luxury — it’s a necessity. At AMCON, we are dedicated to developing efficient and secure AI systems to optimize our internal workflows. A key focus lies in the development of a local Large Language Model (LLM) that operates with Retrieval-Augmented Generation (RAG) and ReACT agents. Data privacy is a top priority: all data remains on local servers and is never transmitted to the internet.
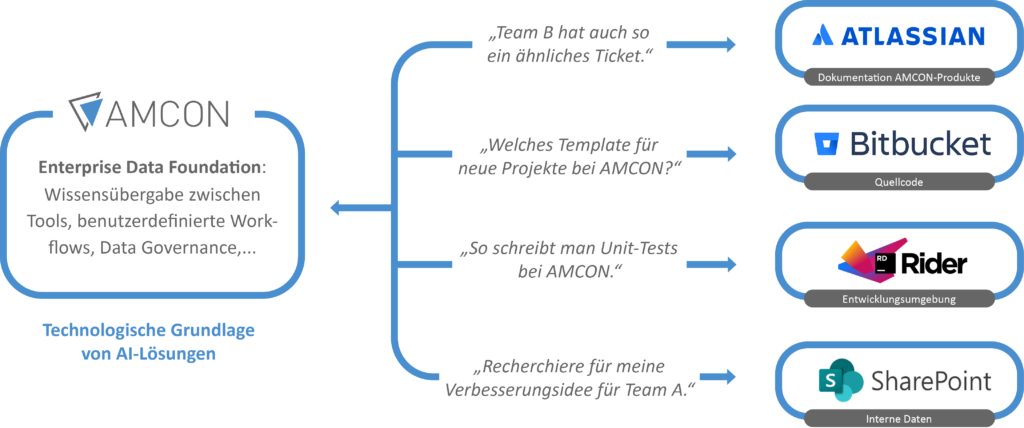
AI Terminology and Key Concepts
What are LLMs?
Large Language Models (LLMs) such as GPT-4, Llama 3.2, or Gemini 2.0 are AI systems designed to process and generate natural language. They can analyze text, create summaries, or even generate code. These models are based on transformer architectures and use mechanisms like attention to make context-aware predictions.
Embedding & RAG
Embedding models convert text into numerical vectors, enabling AI systems to detect relationships between words, sentences, or entire documents. RAG (Retrieval-Augmented Generation) enhances LLMs by incorporating external knowledge sources. This means that the model doesn’t rely solely on its pre-trained data but can retrieve relevant information from internal databases or documents. RAG works in two phases:
The retrieval phase, which identifies relevant documents.
The generation phase, where the AI formulates an informed response based on the retrieved content.
ReACT-Agenten
ReACT (Reasoning + Acting) is an approach that allows AI agents to do more than just respond to prompts. They are capable of complex reasoning and action execution. For example, they can intelligently evaluate data from tools like Jira or Confluence. By combining reinforcement learning with rule-based decision-making, these agents can autonomously prioritize requests and delegate tasks. They have access to a range of tools which they use as needed — such as querying APIs, searching internal data sources, or retrieving external information.
Use Case: Local LLM at AMCON
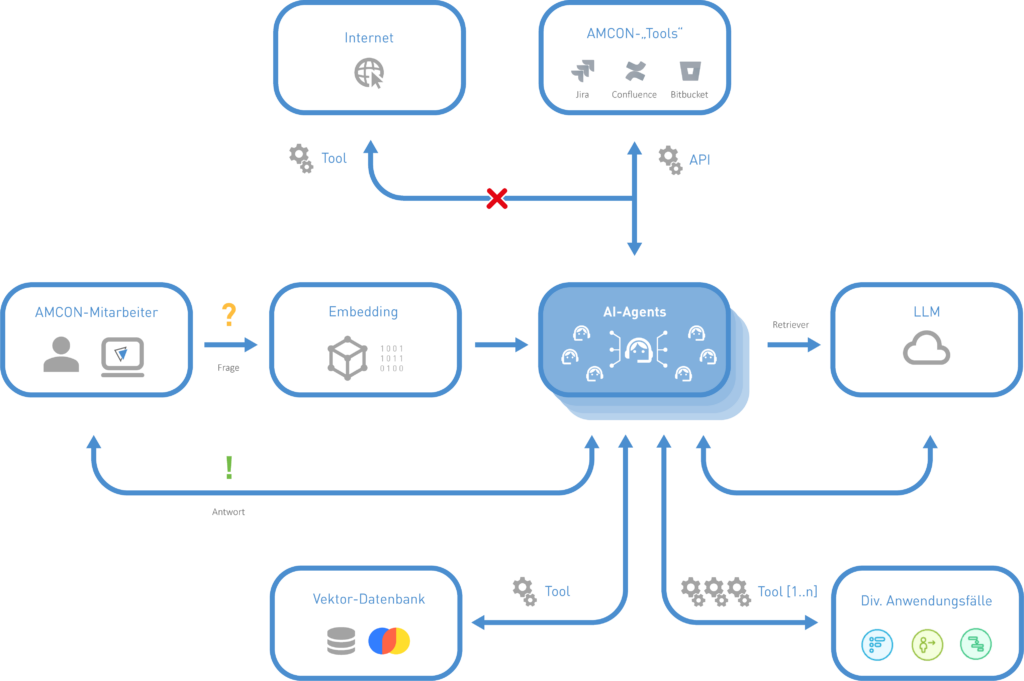
Technological Implementation
The system is built on several key components:
Data & Retrieval
Documents and content from Jira and Confluence are systematically processed and prepared for the LLM. This is achieved using a combination of regular expressions for text extraction and transformer-based models for semantic analysis.
Embedding & RAG
Documents are transformed into vector representations, enabling the model to access relevant information effectively. For this, we use the multilingual-e5-large embedding model.
Backend & Model Access
An internal API connects various applications with the AI system. We use FastAPI to build the API interface and ONNXfor efficient model inference.
The ReACT agent can communicate with the APIs of Confluence and Jira to retrieve relevant information on demand. This is facilitated through the Atlassian Python API, which is tailored for both Jira and Confluence.
Frontend
A user-friendly web interface for seamless interaction with the AI model is currently under development.
Technologies in Use
Vector storage & retrieval: ChromaDB
Language models: Llama 3.2 and Gemma
Frameworks: LangChain and LangGraph orchestrate complex interactions between agents, data sources, and retrieval components.
Development Challenges
Data Privacy and Security
Since all data is stored locally, we had to ensure that the system never accesses external servers. Robust access controls are essential so that only authorized users can view sensitive information. We implement this using OAuth 2.0 and role-based access control (RBAC).
Model Optimization
Running an LLM locally requires powerful hardware resources. We optimized the model to strike a balance between performance and efficiency. Techniques such as quantization (e.g. via Hugging Face’s bitsandbytes) and knowledge distillation were used to reduce memory and compute requirements.
Integration with Existing Systems
Seamlessly integrating with Jira and Confluence posed a challenge due to diverse data formats. Developing specialized retrievers played a critical role. By combining keyword-based and semantic search methods, we ensure highly efficient and precise information retrieval.
Outlook: The Future of AI at AMCON
In the coming years, we will focus on continuously improving and expanding the system:
Inference Optimization
Accelerating response times and improving precision through specialized model architectures and more efficient processing pipelines.
Expanded Agent Functionality
Development and implementation of new AI agents tailored to specific business tasks, including:
Code Improvement Agent:
Analyzes existing code, identifies optimization opportunities, and suggests more efficient solutions.Onboarding Agent:
Assists new employees by providing relevant documentation and company policies during their onboarding process.Project Management Assistant:
Supports task coordination, resource allocation, and tracking of project progress.Templating Agent:
Automates the creation of templates and standard documents to boost operational efficiency.
Next-Generation Language Models
Integration of newer and more powerful LLMs, such as future versions of Llama, DeepSeek, and domain-specific embedding models.
Adaptive Tool Use by Agents
Agents will be equipped with a flexible toolchain, allowing them to dynamically select and apply tools such as API queries, semantic search, or external data retrieval, depending on the task.
Enhanced Retrieval Methods
Implementation of hybrid search techniques that combine semantic embedding with classical indexing for more accurate and context-aware information retrieval.
Scalability and Infrastructure
Evaluation and adoption of new hardware and software solutions to scale the AI architecture, including decentralized processing and specialized AI accelerators.
Improved Integration with Business Processes
Ensuring seamless integration of the AI system into existing workflows and applications to further increase operational efficiency.
Conclusion
With the development of a local LLM system, AMCON has taken a significant step toward AI-driven process optimization. Through the use of RAG and ReACT agents, company knowledge can be leveraged more effectively — without compromising data privacy.
The future of AI at AMCON lies in the continuous advancement of these technologies to create maximum value for employees. At the same time, we remain closely aligned with proven DevOps and MLOps strategies to streamline the development cycle and ensure continuous improvement.